Apache Kafka
Kafka는 대용량의 실시간 로그 처리에 특화되어 설계된 시스템으로, 메시지를 topic을 통해 카테고리화 하는 pub-sub 모델을 이용합니다. 이 모델에서 메시지의 생산자는 topic에 대한 정보만 알고 있으며, 수신자도 마찬가지로 topic만 바라보는 형태가 됩니다. (생산자와 소비자 모두 하나 이상의 topic을 대상으로 할 수 있습니다.)
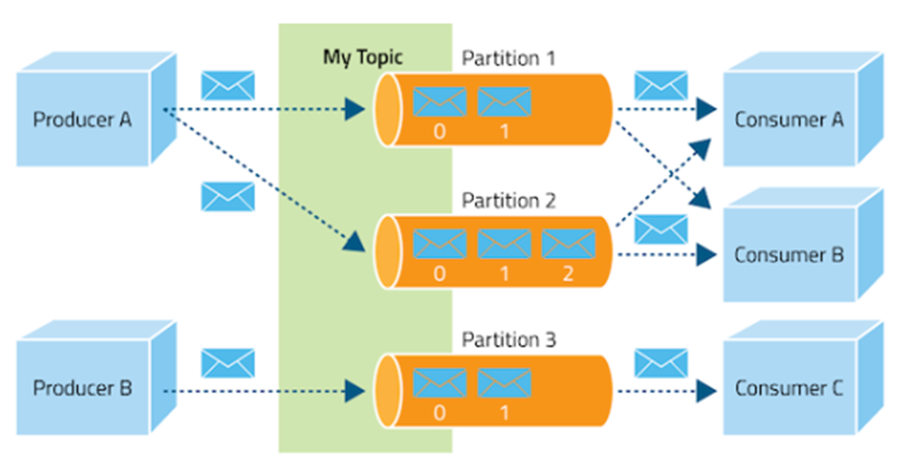
메시지는 topic으로 분류되며, topic은 또 여러 개의 파티션으로 나눠질 수 있습니다. 여기에서 파티션 내의 한 칸을 '로그'라고 하며, 각 데이터는 로그에 순차적으로 삽입됩니다.
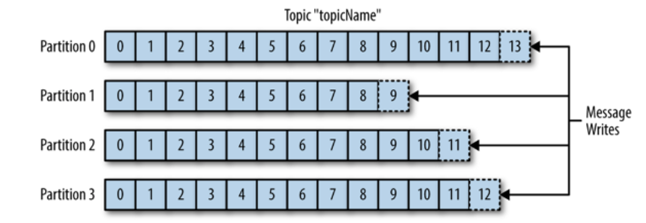
메시지 소비자는 topic을 구독함으로써 자신의 H/W 성능에 맞게 조절해가면서 소비가 가능해집니다. 이 때 소비를 했다는 표시는 각 파티션에 존재하는 Offset의 위치를 통해 관리하며, 혹시나 프로그램이 죽었다 다시 살아나도 마지막으로 읽었던 위치에서부터 다시 읽어들일 수 있게 됩니다.
Kafka는 파일 시스템을 이용하기 때문에 HDD만 충분하다면 메시지의 보존 기간을 여유롭게 잡아도 성능에는 영향을 미치지 않는다는 장점이 있습니다.
| 구분 | 설명 |
| 최초 배포일 | 2011. 01 |
| 라이선스 | Apache License 2.0 |
| 개발 언어 | Java, Scala, Python |
| 클라이언트 지원 언어 | C, C++, Python, Go, Erlang, .NET, Node.js, PHP, Swift, Java, ... |
| 지원 프로토콜 | TCP/IP (단순한 메시지 헤더를 통해 프로토콜에 의한 오버헤드 감소) |
| 특징 | - 대용량의 실시간 로그 처리에 특화되어 설계된 시스템 - 상산자 중심적이며, 저 지연율(Low latency)를 보장하며 메시지 전달 - 초당 100,000개 정도의 메시지 처리 가능 - 메시지를 메모리에 저장하는 타 프로젝트와 달리, Kafka는 파일에 저장하기 때문에 문제가 발생하거나 처리 로직이 변경된 경우 소비자가 메시지를 처음부터 다시 처리할 수 있음 - 소비자가 브로커로부터 메시지를 직접 가지고 가는 방식으로 동작하기 때문에, 소비자가 자신의 처리능력만큼의 메시지만 가져갈 수 있음 - 메시지를 쌓아 두었다가 주기적으로 처리하는 배치 방식의 구현 가능 - 스트림 처리 라이브러리인 Kafka Streams 제공 |
| 선택이 유리한 경우 | - 대용량 메시지의 처리가 필요한 경우 - 한 번 전송한 메시지를 다시 읽을 필요가 있는 경우 - 메시지 순서를 보장해야 하는 경우 |
'구축 & 운영 > RabbitMQ' 카테고리의 다른 글
| Web STOMP 플러그인 설치 (0) | 2022.03.19 |
|---|---|
| RabbitMQ 설치 (0) | 2022.03.19 |
| 메시지 브로커 비교 (Apache Kafks vs RabbitMQ vs ActiveMQ) (0) | 2022.03.08 |
| ActiveMQ 조사 (0) | 2022.03.08 |
| RabbitMQ 조사 (0) | 2022.03.08 |